TL;DR: RoboMME is a large-scale benchmark for memory-augmented robotic manipulation, evaluating how well models remember, reason, and act across temporal, spatial, object, and procedural memory.
Memory is critical for long-horizon and history-dependent robotic manipulation. Such tasks often involve counting repeated actions or manipulating objects that become temporarily occluded. Recent vision-language-action (VLA) models have begun to incorporate memory mechanisms; however, their evaluations remain confined to narrow, non-standardized settings. This limits their systematic understanding, comparison, and progress measurement. To address these challenges, we introduce RoboMME: a large-scale standardized benchmark for evaluating and advancing VLA models in long-horizon, history-dependent scenarios. Our benchmark comprises 16 manipulation tasks constructed under a carefully designed taxonomy that evaluates temporal, spatial, object, and procedural memory. We further develop a suite of 14 memory-augmented VLA variants built on the π0.5 backbone to systematically explore different memory representations across multiple integration strategies. Experimental results show that the effectiveness of memory representations is highly task-dependent, with each design offering distinct advantages and limitations across different tasks.
Building on RoboMME, we construct a family of memory-augmented vision-language-action (VLA) models based on the π0.5 backbone, collectively termed the MME-VLA suite. We systematically compare different memory representations and their integration mechanisms.
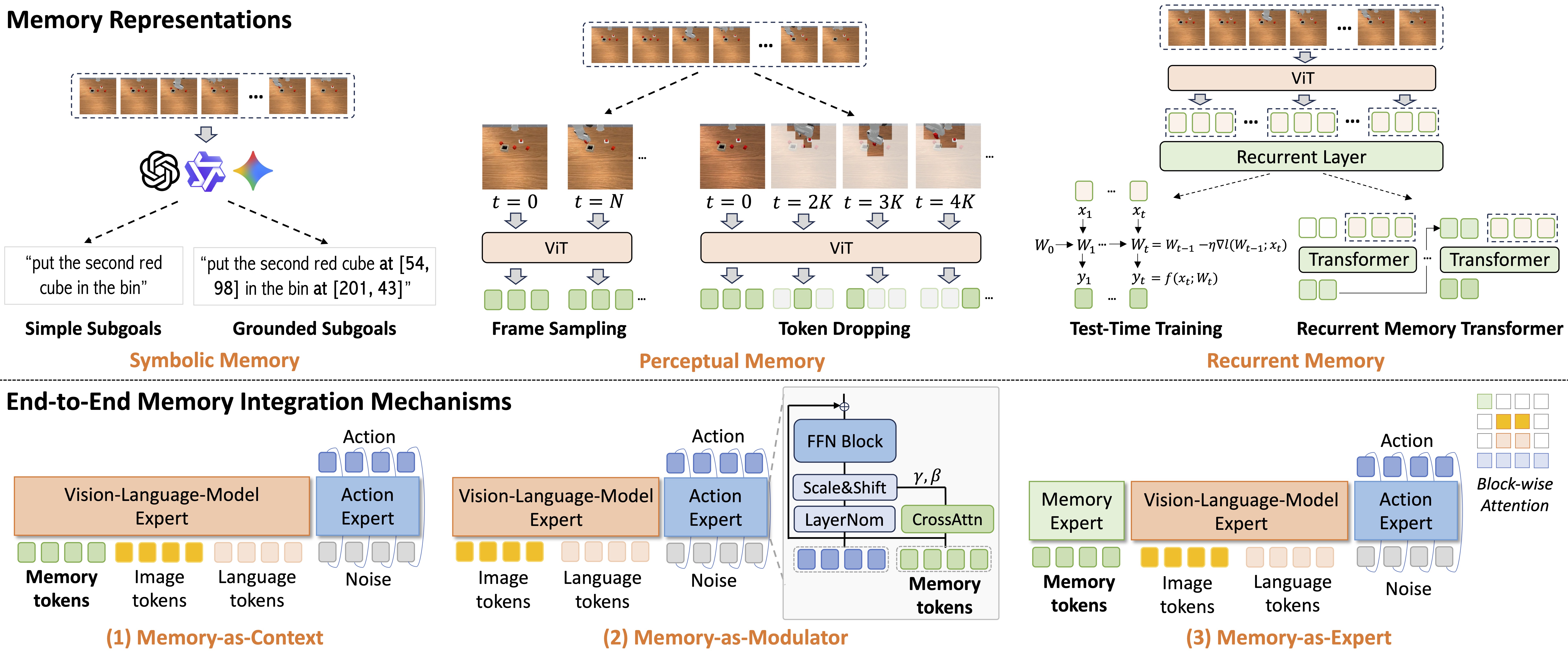
We fine-tune a total of 14 memory-augmented VLA variants based on π0.5:
| Memory Representation | Method | Subgoal Predictor | Integration Mechanism |
|---|---|---|---|
| Symbolic | SimpleSG, GroundSG | Gemini, QwenVL, Oracle | -- |
| Perceptual | TokenDrop, FrameSamp | -- | Context, Modul, Expert |
| Recurrent | TTT, RMT | -- | Context, Modul, Expert |
Naming Convention: Method+Integration Mechanism/Subgoal Predictor, e.g., FrameSamp+Modul or SimpleSG+QwenVL
Key Takeaways:
More specifically, we investigate the following research questions (RQs):
Across all MME-VLA variants:
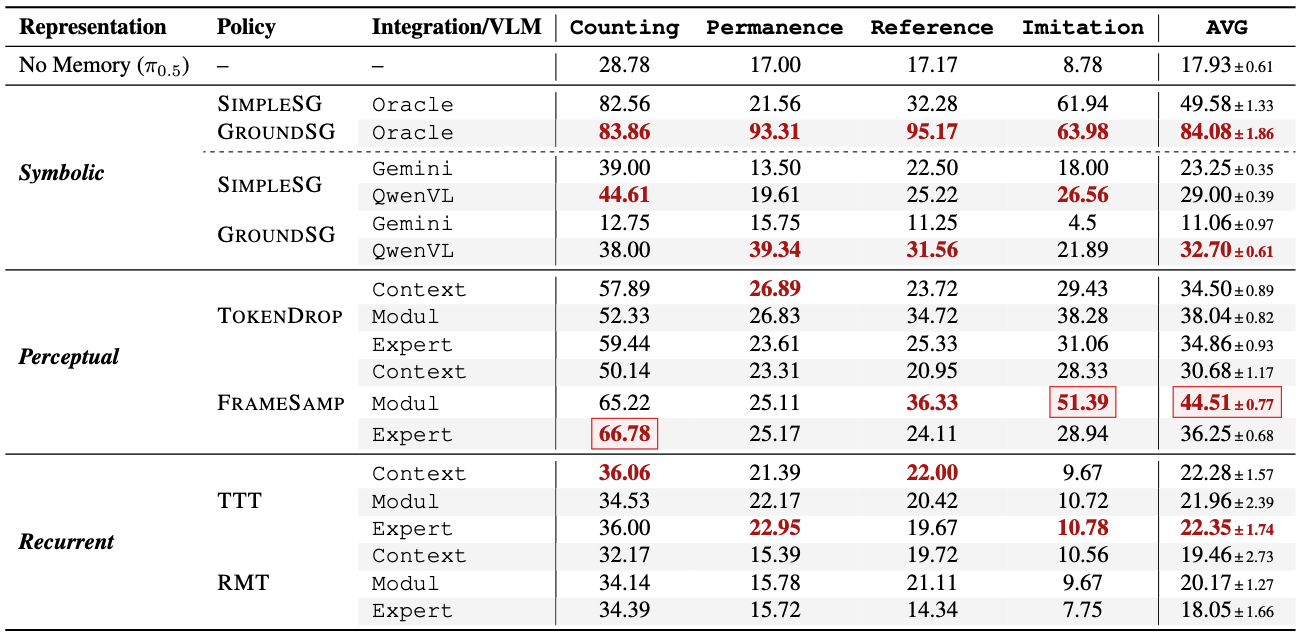
High-level symbolic reasoning is powerful yet not sufficient on its own:
Humans are strong but not perfect on RoboMME:
Different memory designs provide complementary strengths:

To better analyze the effectiveness of memory representations, we group the 16 tasks by their primary functional requirements as shown below:
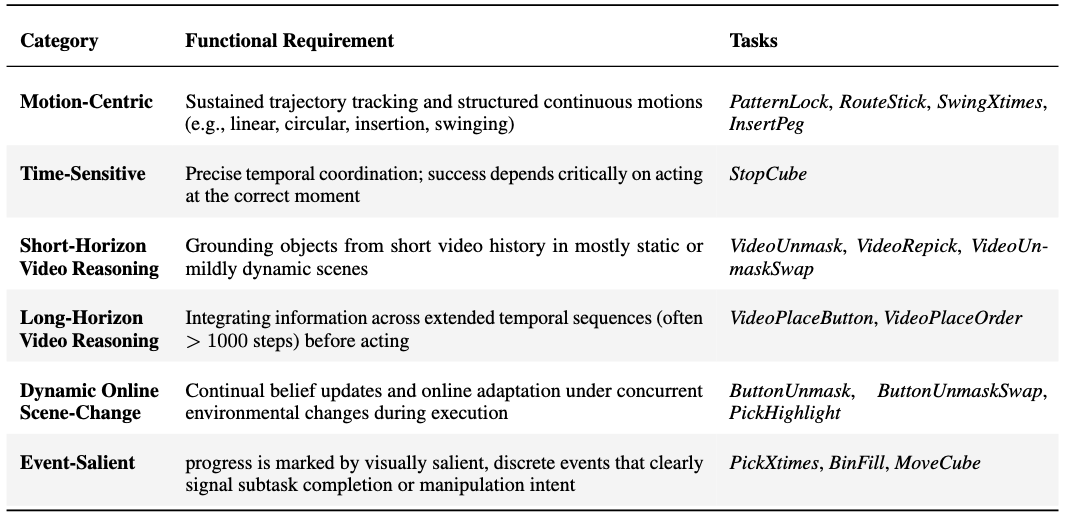
View radar chart by task characteristics on the leaderboard →
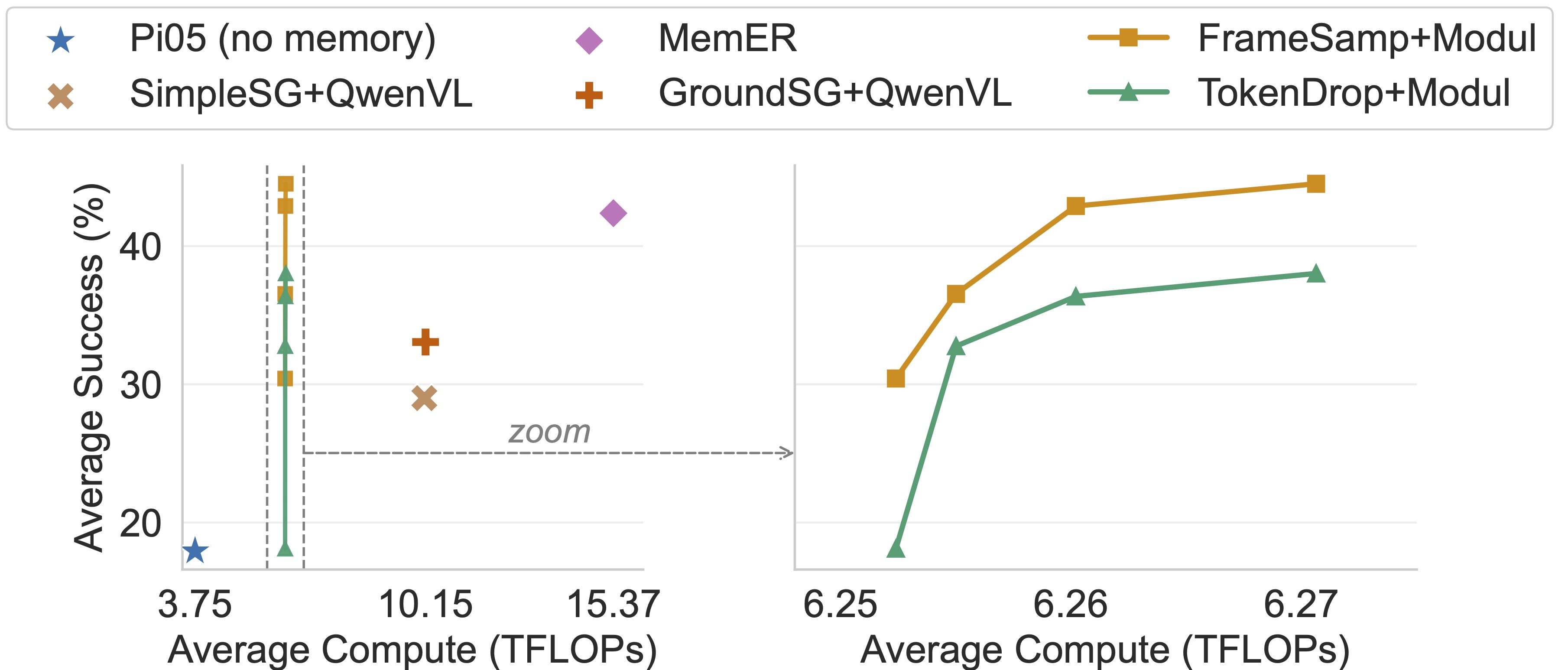
Perceptual memory achieves the best efficiency-performance balance:
Yes. We evaluate four real-world tasks designed to mirror simulation tasks on each task suite:
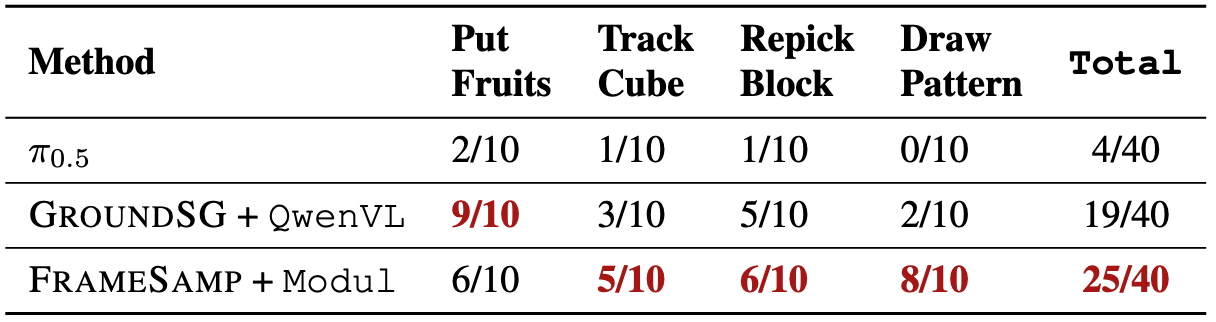
The results exhibit similar patterns: Symbolic Memory performs best on counting (PutFruits), while Perceptual Memory excels on motion-centric tasks (DrawPattern). On the remaining tasks, both achieve comparable performance.

For demonstration purposes, we visualize only the first 10 episodes for each task (the full evaluation contains 50). In simulation experiments, we use the front-view images for memory feature construction or VLM subgoal prediction. For the GroundSG policy, we overlay the predicted grounding information as yellow dots on the front-view images for visualization when it is available. Red-bordered frames indicate the video-based initial observation before execution.
We evaluate four real-world tasks—PutFruits, TrackCube, RepickBlock, and DrawPattern—designed to mirror the BinFill, VideoUnmask/VideoUnmaskSwap, VideoRepick, and PatternLock tasks in simulation. Real-world results exhibit similar patterns to simulation, validating the transferability of our findings.
In real-world experiments, we use the right-shoulder view images for memory feature construction or VLM subgoal prediction. For the GroundSG policy, we overlay the predicted grounding information as red dots on the right-shoulder view images for visualization when it is available. Red-bordered frames indicate the video-based initial observation before execution.